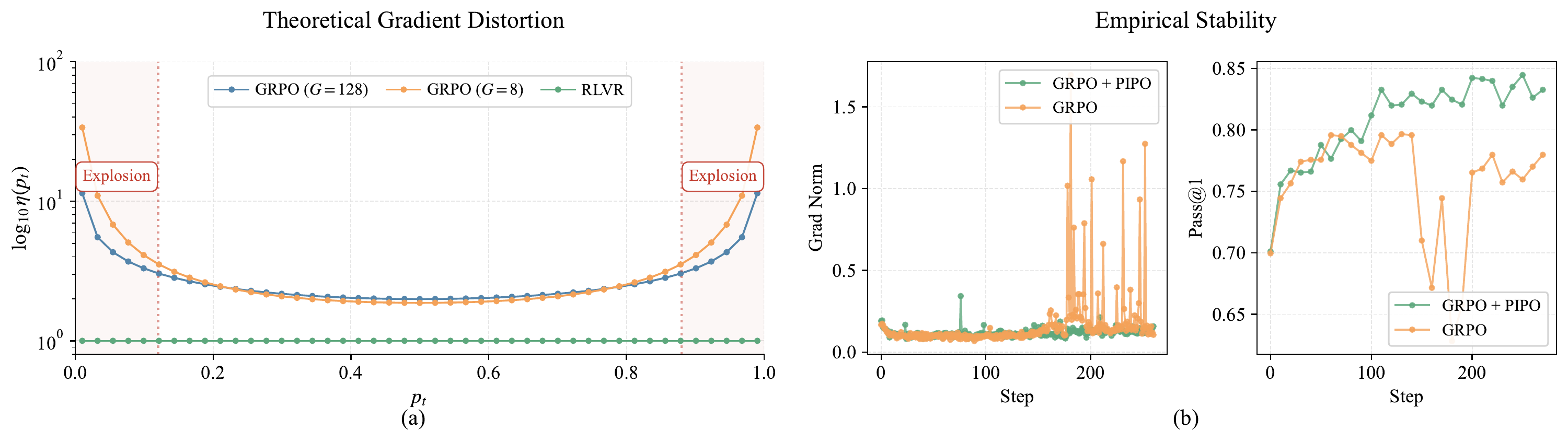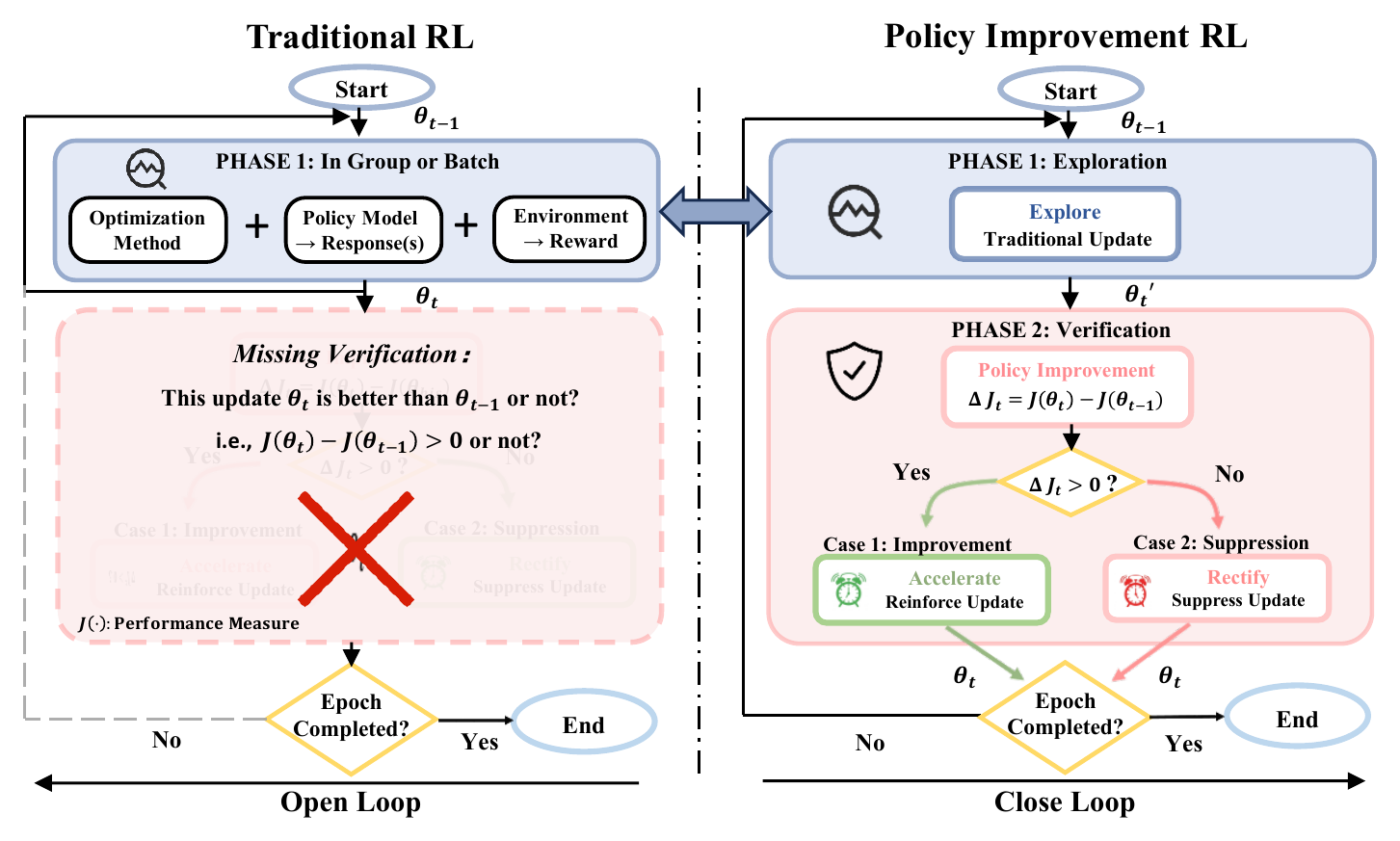
Reinforcement learning has become a central post-training paradigm for improving LLM and agent capabilities. Yet existing RL post-training methods share a common blind spot: they construct local learning signals from sampled trajectories, rewards, or feedback-conditioned targets, then update the policy without explicitly verifying whether the resulting policy outperforms its predecessor. Optimizing these local signals does not necessarily produce a better policy, while finite sampling, generation stochasticity and feedback noise can further widen this gap.
We argue that the missing ingredient is policy improvement feedback: the ability to measure progress across policy iterations. We introduce Policy Improvement Reinforcement Learning (PIRL), which formulates inter-iteration performance gain as an explicit objective structurally aligned with final task performance.
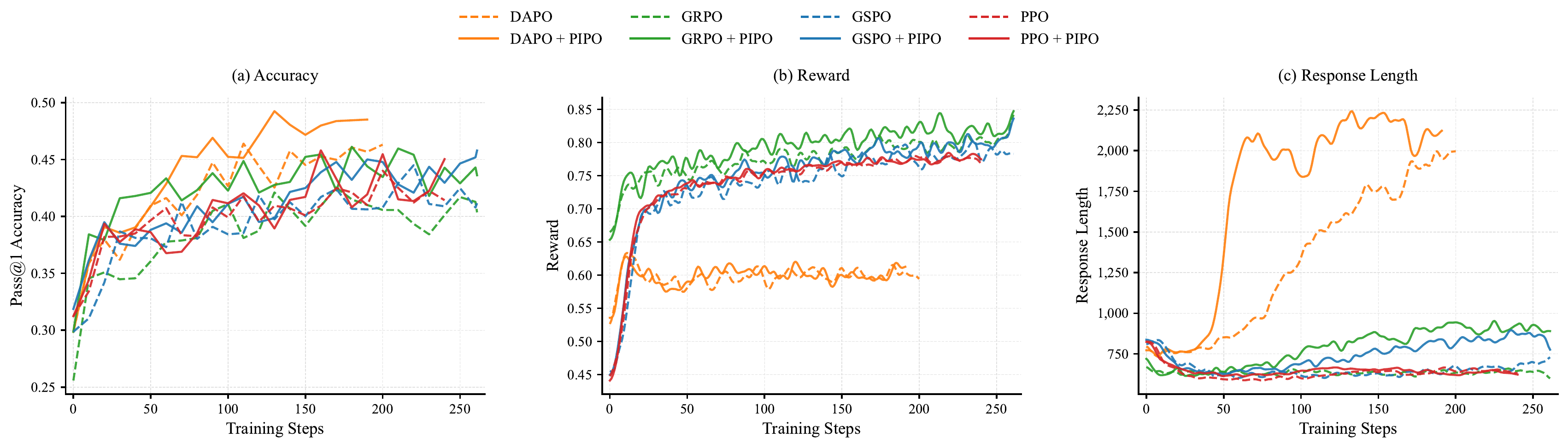
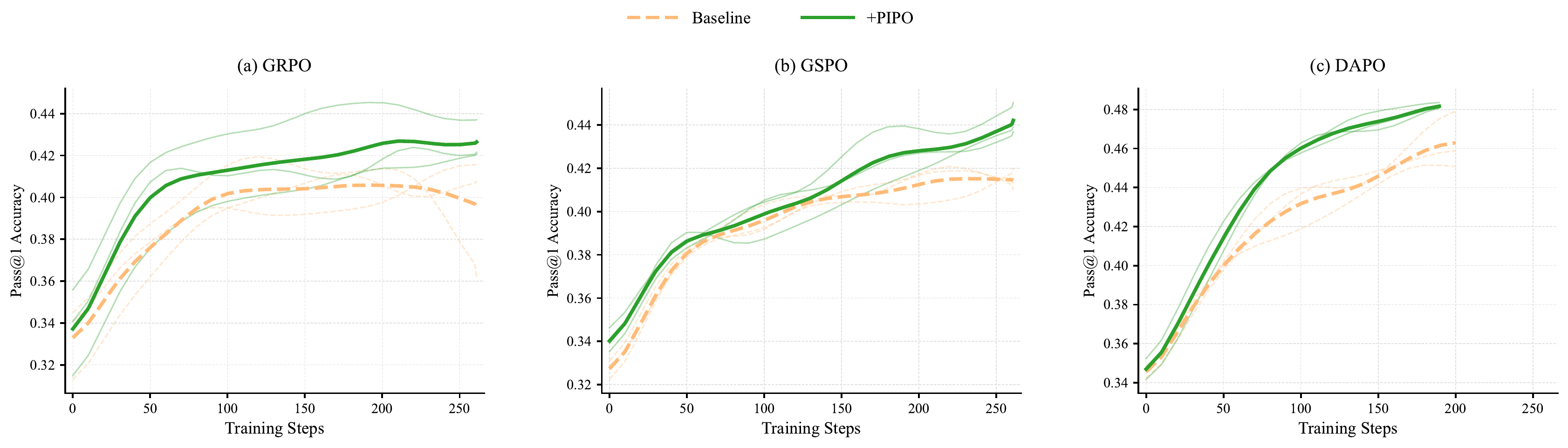
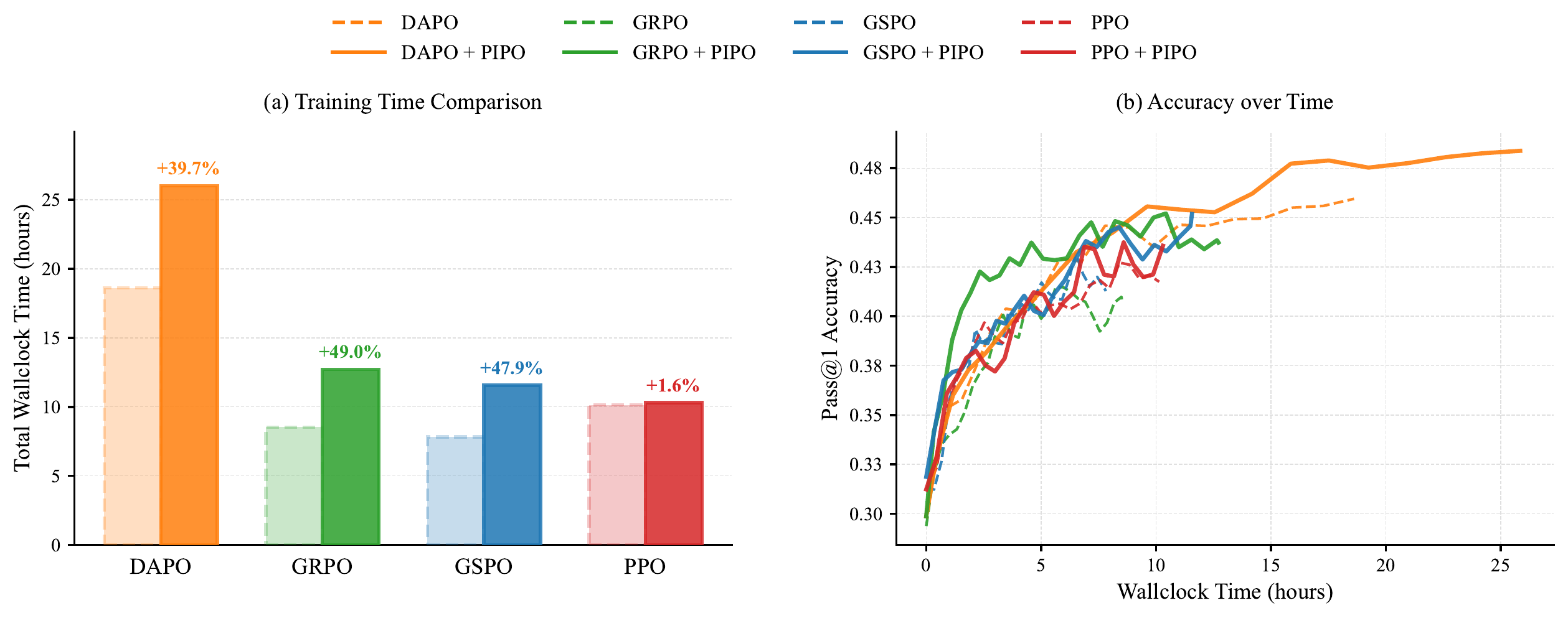
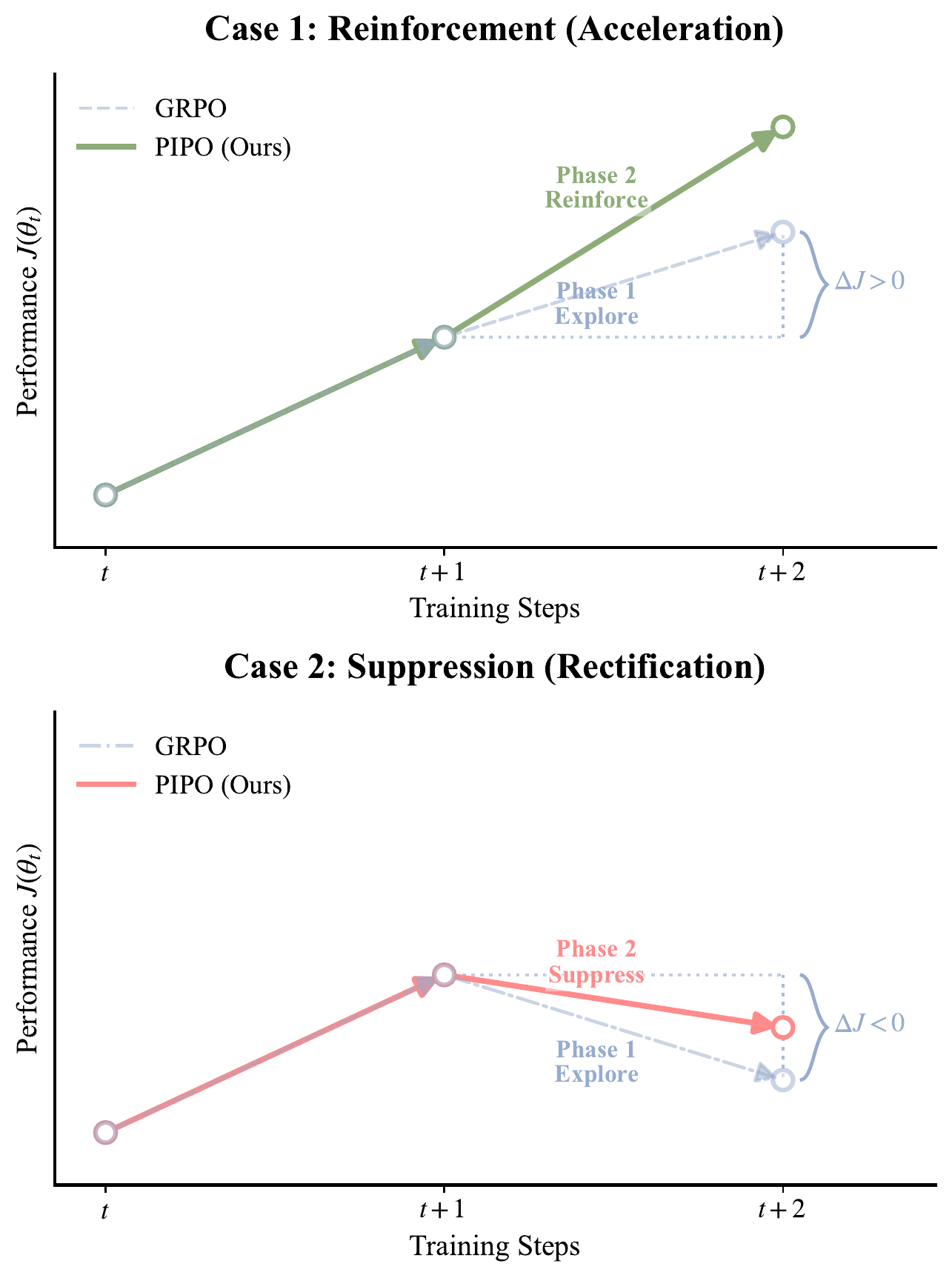
Building on PIRL, we propose Policy Improvement Policy Optimization (PIPO), a plug-in closed-loop framework that verifies the previous update against a sliding-window historical performance anchor. PIPO uses this improvement feedback to modulate the local learning signal of the base policy optimization algorithm, reinforcing updates associated with measured progress and suppressing those associated with performance drops.
We provide theoretical evidence that PIPO locally aligns policy updates with the PIRL improvement objective. Experiments on mathematical reasoning, code, tool-use, and self-distillation settings show that PIPO yields consistent gains across PPO, group-relative, and self-distillation policy optimization families.